Posted on November 7, 2023 in Uncategorized by Eric Lease Morgan
Today (September 21, 2023) I got a tour of the University’s power plant, and I believe we could learn from them.
Today, I had the opportunity to get a tour of the University’s power plant. The facility was large, loud, clean, efficient, and seemingly operated by dedicated professionals with wide and deep experience. Much of the power is generated through the burning of natural gas, but once water is turned into steam it is used over and over, again and again. The power plant supplements its services with geo-thermal energy, solar power, and water-spun turbines. The plant works in cooperation the other power utilities in the area, but it also has the ability be operate completely independently. In a great many ways, the power plant is self-sufficient, more over, it continues to evolve and improve both its services and operations.
I then asked myself, “What is the ‘business’ of the University?”, and the answer alludes to teaching, learning, research, and Catholicism. Yet, the power plant really has nothing to do with those things. Yet, now-a-days, it seems fashionable to outsource non-core aspects of a workplace. Companies will lease a building, and hire other people to do the maintenance and cleaning. Restaurants will not launder their own napkins nor table cloths. Services are contracted to mow our grass or plow our snow. In our own workplace, we increasingly outsource digital collection, preservation, and metadata creation operations. For example, to what degree are we really & truly curating the totality of theses and dissertations created here at Notre Dame? Similarly, to what degree are we curating the scholarly record?
I asked the leader of the tour, “Running a power plant is not the core business of the University, so why is it not outsourced?” And the answer was, “Once, such was considered, and there was a study; it was deemed more cost effective to run our own plant.” I then asked myself, “To what degree have we — the Libraries and the wider library profession — done similar studies?” Personally, I have not seen nor heard of any such things, and if they do exists, then to what degree have they been rooted in antitotal evidence?
Our University has a reputation for being self-sufficient and independent. Think football. Think the power plant. Think the police, fire, religious, postal, food, grounds, housing, and banking services. Why not the Libraries? How are we any different?
I assert that if we — the Libraries — were to divert some of our contracted services and licensing fees to the development of our people, then we too would become more independent, more knowledgable, and more able to evolve with the ever-changing environment, just like the power plant. After all, we too are large, clean, efficient, and operated by dedicated professionals with wide and deep experience. (We’e not loud.)
Given a short-term and limited period of time, I suggest we more systematically digitize a greater part of our collections, pro-actively collect born-digital materials freely available on the ‘Net, catalog things at scale and support the Semantic Web, etc. Along the way our skills will increase, new ways of thinking will emerge, and we will feel empowered as opposed to powerless. Only after we actually give this a try — do a study — will we be able to measure the cost-effectiveness of outsourcing. Is outsourcing really worth the cost?
Again, the University has a reputation for being independent. Let’s try to put some of that philosophy into practice here in the Libraries.
Posted on April 1, 2022 in Distant Reader by Eric Lease Morgan
I asked a colleague (Parker Ladwig) if there was a blog he thought might be worthy of archiving, and he mentioned Issues in Science and Technology Librarianship (ISTL). I took it upon myself to see what I could do.
After looking more closely at the site, I guessed the underlying technology was not blog technology but rooted in the venerable OJS journal publishing system, and OJS robustly supports a protocol called OAI-PMH. Luckily I had previously written a suite of software used to harvest all the bibliographic information and content from (OJS) OAI-PHM sites. Consequently, in a matter of about 30 minutes, I was able to create a CSV file listing all the articles along with their authors, titles, abstracts, URLs, etc.
I then ran a program that looped through the CSV file and downloaded (cached) the content. Thus, all the articles in their original form are found in the (temporarily) linked .zip file. There are about 900 of them.
I then ran the whole thing through my Distant Reader Toolbox, and I am now able to characterize the journal as a whole. For example, after removing bogus files, there are about 850 articles, and the whole corpus is 2.5 million words long. (The Bible is about .8 million words long.) I was then able to create a rudimentary bibliography, which is really only half a step better than the original CSV file.
Do you know what ISTL is about? Science and technology librarianship would be a good guess, but can you elaborate? I can, in a number of ways. For example, if I compute statistically significant keywords against the text, I can visualize the result as a word cloud. Now you know more, and in what proportions.
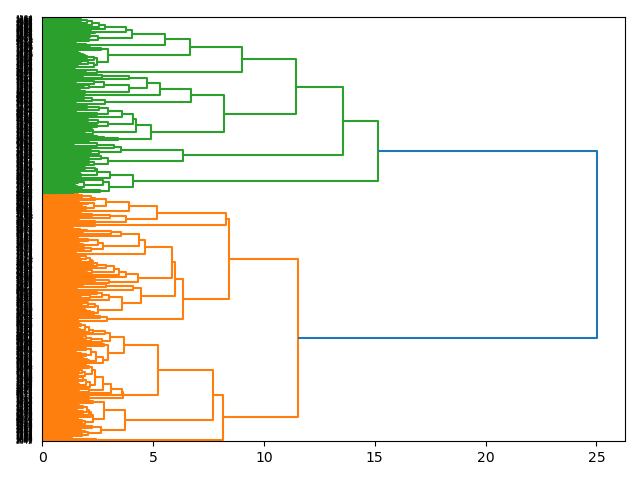
Rudimentary clustering of the data returns two possible themes, but the clustering process (Principle Component Analysis) does not articulate what those themes may be. Still, such an analysis points to what a good topic model might be.
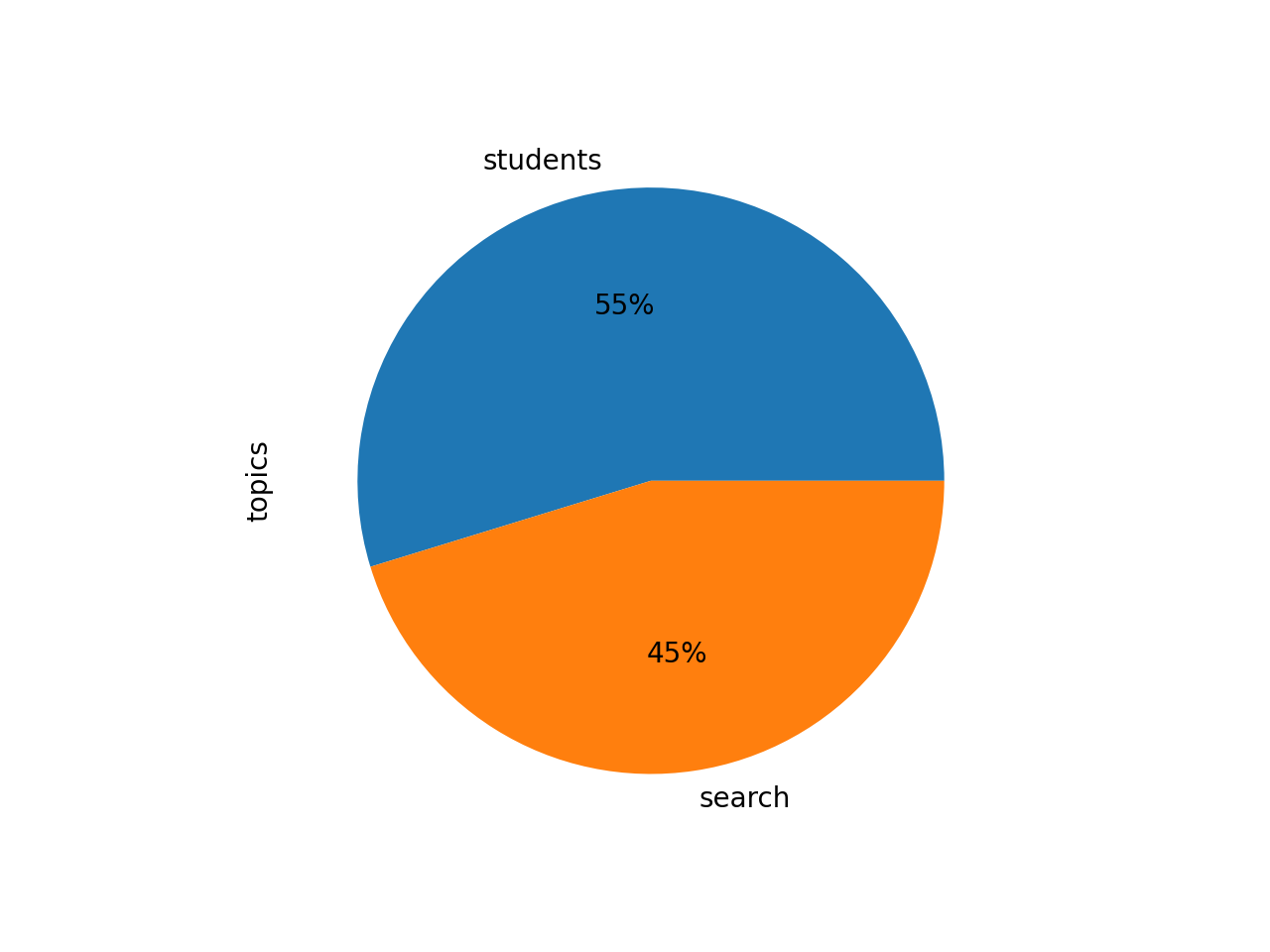
Topic modeling with only two topics, returns two possible, over-arching themes: 1) students, and 2) search. Notice how the students theme is really about people, and the search theme seems to be about searching stuff:
topic weights features
students 0.54019 students data research librarians faculty univ...
search 0.44664 search journals web access research articles d...
In terms of proportions, the pie chart of the weights mirrors the clustering analysis.
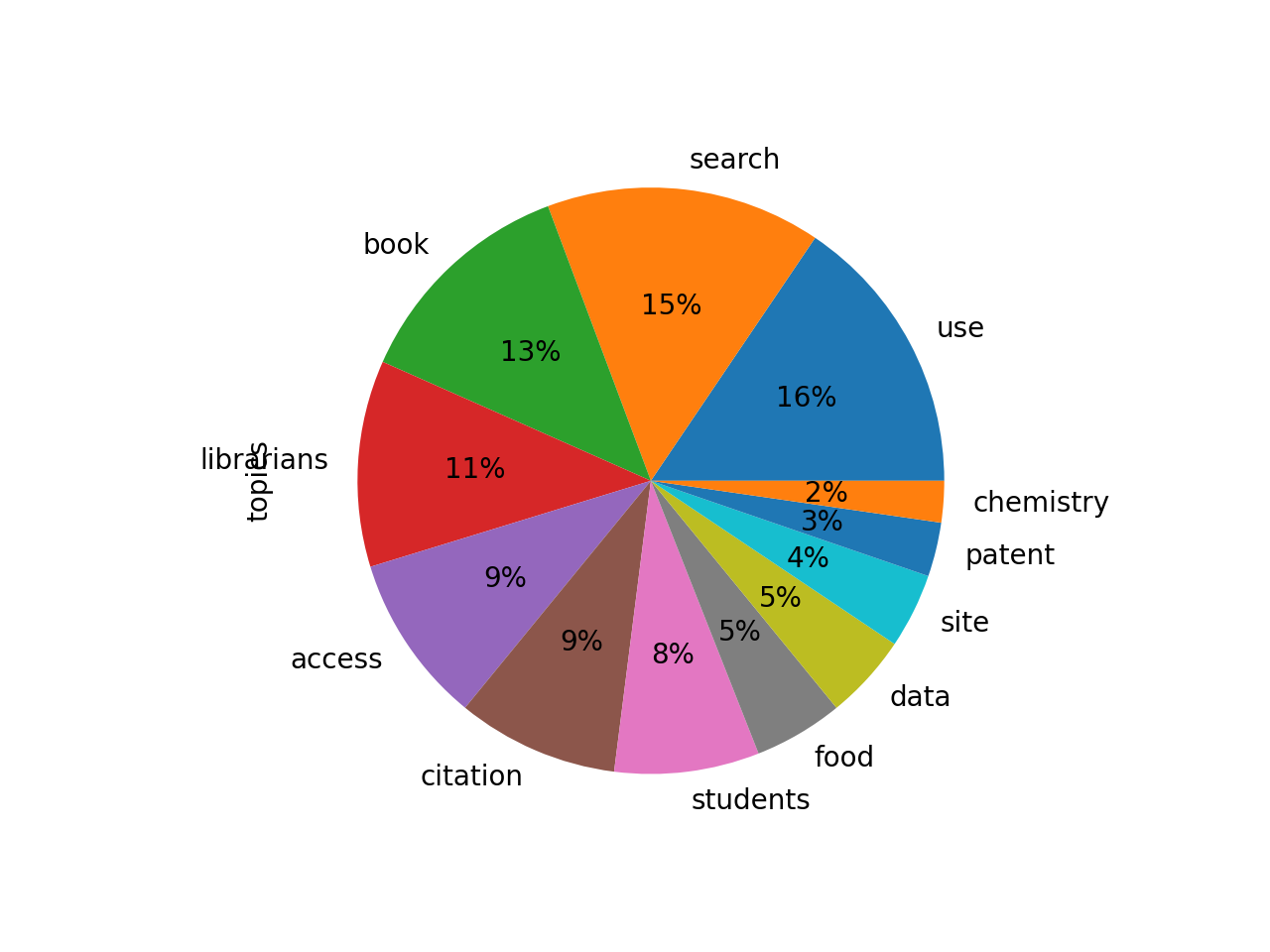
After a bit more modeling, the idea of search is still evident, but the theme of students has broken down into different types of people and different things being searched:
topic weights features
use 0.34272 use faculty survey services new staff university
search 0.33438 search web database users results databases also
book 0.27892 book technology work new internet example many
librarians 0.25108 librarians research technology university educ...
access 0.20613 access journals electronic open research publi...
citation 0.19648 citation study journals research analysis arti...
students 0.17608 students literacy research instruction course ...
food 0.10850 food site resources environmental research agr...
data 0.10367 data research management researchers gis servi...
site 0.09101 site resources links web provides history rese...
patent 0.06577 patent yes patents titles databases journals d...
chemistry 0.05041 chemistry chemical structure molecular data bi...
Upon closer inspection of the keywords, the word soil piqued my interest, so I created a full text index and searched for “title:soil OR keyword:soil”. I got three records:
Your search (title:soil OR keyword:soil) against the study carrel named
"istl" returned 3 record(s):
id: 2495
author: Pellack, Lorraine J.
title: Soil Surveys — They're Not Just for Farmers.
date: 2009-09-01
summary: Soil surveys do contain inventories of the soils of an area;
however, they also contain a wealth of tabular data that help interpret
whether a location is suitable for a given use, such as a playground, a
golf course, or a highway. This guide will describe soil surveys, their
uses, and uniqueness.
keyword(s): library; soil; surveys; u.s
words: 3003
sentence: 151
flesch: 59
cache: /Users/eric/Documents/reader-library/istl/cache/2495.htm
txt: /Users/eric/Documents/reader-library/istl/txt/2495.txt
id: 2420
author: Bracke, Marianne Stowell
title: Agronomy: Selected Resources
date: 2007-07-01
summary: This web bibliography, or webliography, contains links and
descriptions of agronomy web sites that cover general and background
information, crop science, soil science, resources for K-12 teachers,
databases, freely-available and subscription-based journals, and
organizations. Only a select number of sites that focused on crop
science, soil science, or a particular sub-area (e.g., corn) were
included due to the large number of sites in existence.
keyword(s): agronomy; crop; information; plant; science; site; soil
words: 5135
sentence: 265
flesch: 39
cache: /Users/eric/Documents/reader-library/istl/cache/2420.htm
txt: /Users/eric/Documents/reader-library/istl/txt/2420.txt
id: 1984
author: Harnly, Caroline D.
title: Sustainable Agriculture and Sustainable Forestry: A
Bibliographic Essay: Theme: All Topics
date: 2004-08-14
summary: The authors found that there is no clear preference in
the marketplace to the many approaches to achieving sustainable forest
management. Peter F. Ffolliott, et al.'s book, Dryland Forestry,
details how to manage both the biophysical and socioeconomic aspects
of environmentally sound, sustainable forest management in dryland
environments.
keyword(s): agricultural; book; edited; farming; food; forest; forest
management; management; new; papers; press; soil; sustainability;
sustainable; sustainable agriculture; sustainable forestry; systems; topics
words: 14403
sentence: 990
flesch: 43
cache: /Users/eric/Documents/reader-library/istl/cache/1984.htm
txt: /Users/eric/Documents/reader-library/istl/txt/1984.txt
Well, that’s enough for now, but the point is this:
As librarians we collect, organize, preserve, and disseminate data, information, and knowledge. These are the whats of librarianship, and they change very slowly. On the other hand, the hows of librarianship — card catalogs versus OPAC, MARC versus linked data, licensing versus purchasing, reference desking versus zooming, just-in-time collection versus just-in-case collection, etc. — change much faster with changes in the political environment and technology. Harvesting things from the Web and adding value to the resulting collection may be things we ought to do more actively. The things outlined above are possible examples.
There is clearly value in identifying the parts of “the Web” that aren’t being collected, preserved, and disseminated to scholars. But in an era when real resources are limited, and likely shrinking, proposals to address these deficiencies need to be realistic about what can be achieved with the available resources. They should be specific about what current tasks should be eliminated to free up resources for these additional efforts, or the sources of (sustainable, not one-off) additional funding for them.
Posted on December 6, 2021 in Distant Reader by Eric Lease Morgan
A number of things have been happening with the Distant Reader, and I hope to share them here.
Reader in use – The Reader is currently being used in a number of ways. For example, it has become a part of a data science class here at Notre Dame. It is being used in project to predict possible violent attacks. I use it on a regular basis and it has helped me understand: 1) the role of small farmers in developing countries, 2) how the Psalms have evolved over time, 3) the degree I can summarize thousands of medical documents, and 4) the similarities and difference between the novels of Jane Austen.
Bibliography – Over the past few years, I have written a number of blog postings describing the Reader, and it is linked here in the hopes of providing you with more meaningful messages about: 1) what the Reader is, 2) what it is designed to do, and 3) how to use it.
Reader Toolbox – The Distant Reader takes sets of unstructured data as input, applies various text mining techniques against it, and outputs a set of structured data intended for analysis — “reading”. These data sets, called “study carrels”, are very amenable to computer processing. Consequently I have developed a thing called the Reader Toolbox which makes it easy to do all sorts of feature extraction (ngrams, parts-of-speech, named entities, URLs, etc.), topic modeling, semantic indexing, and full text indexing against study carrels. Give it a try!
Reader Library – A fledgling collection of previously created study carrels is in the process of being curated. The collection includes about 3,000 carrels on topics ranging from big ideas (love, honor, truth, justice, etc.) to COVID. The content of the carrels comes from places like Project Gutenberg, the HathiTrust, the ‘Net in general, and a data set called CORD-19. In the coming months I hope to create various indexes against the collection. Right now the iterface is functional but pretty raw.
Sponsorships – The Reader has been supported by a number of groups over the past few years. Most recently, support has come from Microsoft’s AI for Health initiative as well as the Pittsburgh Supercomputer Center through an organization called XSEDE. All good things come to an end, and this will soon be true of their support. Thank you very much! I will be looking for a new home for the Distant Reader. Got any ideas?
Just for fun – Lastly, you might want to listen to a podcast. Excellently produced by the folks at Lost In The Stacks, it is a humorous interview where I describe the Reader.
Posted on December 2, 2021 in Distant Reader by Eric Lease Morgan
Over the past few years, I have written a number of blog postings which describe a thing called the Distant Reader. I have reorganized many of these postings into the following bibliography in the hopes of providing you with a more meaningful message about: 1) what the Reader is, 2) what it is designed to do, and 3) how to use it. Happy…. reading!
If nothing else, read these
What is the Distant Reader and why should I care? – The Distant Reader is a tool for reading. It takes an arbitrary amount of unstructured data (text) as input, and it outputs sets of structured data for analysis — reading. Given a corpus of any size, the Distant Reader will analyze the corpus, and it will output a myriad of reports…
Distant Reader “study carrels”: A manifest – The results of the Distant Reader process is the creation of a “study carrel” — a set of structured data files intended to help you to further “read” your corpus. This blog posting describes these files in greater detail.
Introducing the Distant Reader Toolbox – The Distant Reader Toolbox is a command-line tool for interacting with data sets created by the Distant Reader. This posting describes the Toolbox in greater detail.
Tools and features
Distant Reader Workshop Hands-On Activities – This is a small set of hands-on activities presented for the Keystone Digital Humanities 2021 annual meeting. The intent of the activities is to familiarize participants with the use and creation of Distant Reader study carrels. This page is also available as PDF file designed for printing. Introduction The Distant Reader is a tool for…
Searching Project Gutenberg at the Distant Reader – The venerable Project Gutenberg is a collection of about 60,000 transcribed editions of classic literature in the public domain, mostly from the Western cannon. A subset of about 30,000 Project Gutenberg items has been cached locally, indexed, and made available through a website called the Distant Reader. Search the index and create a study carrel from the result. Great practice.
Searching CORD-19 at the Distant Reader – This blog posting documents the query syntax for an index of scientific journal articles called CORD-19. CORD-19 is a data set of scientific journal articles on the topic of COVID-19. As of this writing, it includes more than 750,000 items. Search the index and create a study carrel from the results.
OpenRefine and the Distant Reader – The student, researcher, or scholar can use OpenRefine to open one or more different types of delimited files, files created by the Distant Reader. This posting is an elaboration of this idea.
The Distant Reader and concordancing with AntConc – Concordancing is really a process about find, and AntConc is a very useful program for this purpose. Given a Distant Reader study carrel, AntConc can be very useful.
Wordle and the Distant Reader – Visualized word frequencies, while often considered sophomoric, can be quite useful when it comes to understanding a text, especially when the frequencies are focused on things like parts-of-speech, named entities, or co-occurrences. This posting describes this in more detail
Other
How to use text mining to address research questions – This tiny blog posting outlines a sort of recipe for the use of text mining to address research questions. Through the use of this process the student, researcher, or scholar can easily supplement the traditional reading process. Articulate a research question – This is one of the more difficult parts of the process, and the…
The Distant Reader Workbook – I am in the process of writing a/the Distant Reader workbook, which will make its debut at a Code4Lib preconference workshop in March 2020. Below is both the “finished” introduction and table-of-contents of the workbook
PTPBio and the Reader – The following missive was written via an email message to a former colleague, and it is a gentle introduction to Distant Reader “study carrels”.
Invitation to hack the Distant Reader – We invite you to write a cool hack enabling students & scholars to “read” an arbitrarily large corpus of textual materials. Introduction A website called The Distant Reader takes an arbitrary number of files or links to files as input. [1] The Reader then amasses the files locally, transforms them into plain text files, and…
The Distant Reader and a Web-based demonstration – The following is an announcement of a Web-based demonstration to the Distant Reader: Please join us for a web-based demo and Q&A on The Distant Reader, a web-based text analysis toolset for reading and analyzing texts that removes the hurdle of acquiring computational expertise. The Distant Reader offers a ready way to onboard scholars to…
A Distant Reader Field Trip to Bloomington – Yesterday I was in Bloomington (Indiana) for a Distant Reader field trip. More specifically, I met with Marlon Pierce and Team XSEDE to talk about Distant Reader next steps. We discussed the possibility of additional grant opportunities, possible ways to exploit the Airivata/Django front-end, and Distant Reader embellishments such as: Distant Reader Lite – a…
Posted on October 14, 2021 in Distant Reader by Eric Lease Morgan
This tiny blog posting outlines a sort of recipe for the use of text mining to address research questions. Through the use of this process the student, researcher, or scholar can easily supplement the traditional reading process.
Articulate a research question – This is one of the more difficult parts of the process, and the questions can range from the mundane to the sublime. Examples might include: 1) how big is this corpus, 2) what words are used in this corpus, 3) how have given ideas ebbed & flowed over time, or 4) what is St. Augustine’s definition of love and how does it compare with Rousseau’s?
Identify one or more textual items that might contain the necessary answers – These items may range from set of social media posts, sets of journal articles, sets of reports, sets of books, etc. Point to the collection of documents.
Get items – Even in the age of the Internet, when we are all suffering from information overload, you would be surprised how difficult it is to accomplish this step. One might search a bibliographic index and download articles. One might exploit some sort of application programmer interface to download tweets. One might do a whole lot of copying & pasting. What ever the process, I suggest one save each and every file in a single directory with some sort of meaningful name.
Add metadata – Put another way, this means create a list, where each item on the list is described with attributes which are directly related to the research question. Dates are an obvious attribute. If your research question compares and contrasts authorship, then you will need author names. You might need to denote language. If your research question revoles around types of authors, then you will need to associate each item with a type. If you want to compare & contrast ideas between different types of documents, then you will need to associate each document with a type. To make your corpus more meaningful, you will probably want to associate each item with a title value. Adding metadata is tedious. Be forewarned.
Convert items to plain text – Text mining is not possible without plain text; you MUST have plain text to do the work. This means PDF files, Word documents, spreadsheets, etc need to have their underlying texts extracted. Tika is a very good tool for doing and automating this process. Save each item in your corpus as a corresponding plain text file.
Extract features – In this case, the word “features” is text mining parlance for enumerating characteristics of a text, and the list of such things is quite long. In includes: size of documents measured in number of words, counts & tabulations (frequencies) of ngrams, readability scores, frequencies of parts-of-speech, frequencies of named entities, frequencies of given grammars such as noun phrases, etc. There are many different tools for doing this work.
Analyze – Given a set of features, once all the prep work is done, one can actually begin to address the research question, and there are number of tools and subprocesses that can be applied here. Concordancing is one of the quickest and easiest. From the features, identify a word of interest. Load the plain text into a concordance. Search for the word, and examine the surrounding words to see how the word was used. This is like ^F on steroids. Topic modeling is a useful process for denoting themes. Load the texts into a topic modeler, denote the number of desired topics. Run the modeler. Evaluate the results. Repeat. Associate each document with a metadata value, such as date. Run the modeler. Pivot the results on the date value. Plot the results as a line chart to see how topics ebbed & flowed over time. If the corpus is big enough (at leaset a million words long), then word embedding is a useful to learn what words are used in conjunction with other words. Those words can then be fed back into a concordance. Full text indexing is also a useful analysis tool. Index corpus complete with metadata. Identify words or phrases of interest. Search the index to learn what documents are most relevant. Use a concordance to read just those documents. Listing grammars is also useful. Identify a thing (noun) of interest. Identify an action (verb) of interest. Apply a language model to a given text and output a list all sentences with the given thing and action to learn what they are with. An example is “Ahab has”, and the result will be lists of matching sentences including “Ahab has…”, “Ahab had…”, or “Ahab will have…”
Evaluate – Ask yourself, “To what degree did I address the research question?” If the degree is high, or if you are tired, then stop. Otherwise, go to Step #1.
Such is an outline of using text mining to address research questions, and there are a few things one ought to take away from the process. First, this is an iterative process. In reality, it is never done. Similarly, do not attempt to completely finish one step before you go on to the next. If you do, then you will never get past step #3. Moreover, computers do not mind if processes are done over and over again. Thus, you can repeat many of the subprocesses many times.
Second, this process is best done as a team of at least two. One person plays the role of domain expert armed with the research question. A person who knows how to manipulate different types of data structures (different types of lists) with a computer is the other part of the team.
Third, a thing called the Distant Reader automates Step #5 and #6 with ease. To some degree, the Reader can do #3, #4, and #7. The balance of the steps are up people.
Finally, the use of text mining to adress research questions is only a supplement to the traditional reading process. It is not a replacement. Text mining scales very well, but it does poorly when it comes to nuance. Similarly, text mining is better at addressing quantitative-esque questions; text mining will not be able to answer why questions. Moreover, text mining is a repeatable process enabling others to verify results.
Remember, use the proper process for the proper problem.
Posted on September 26, 2021 in Distant Reader by Eric Lease Morgan
The Distant Reader Toolbox is a command-line tool for interacting with data sets created by the Distant Reader — data sets affectionally called “study carrels”. See:
The Distant Reader takes an almost arbitrary amount of unstructured data (text) as input, creates a corpus, performs a number of text mining and natural language processing functions against the corpus, saves the results in the form of delimited files as well as an SQLite database, summarizes the results, and compresses the whole into a zip file. The resulting zip file is a data set intended to be used by people as well as computers. These data sets are called “study carrels”. There exists a collection of more than 3,000 pre-created study carrels, and anybody is authorized to create their own.
Study carrels
The contents of study carrels is overwhelmingly plain text in nature. Moreover, the files making up study carrels are consistently named and consistently located. This makes study carrels easy to compute against.
The narrative nature of study carrel content lends itself to quite a number of different text mining and natural language processing functions, including but not limited to:
bibliometrics
full-text indexing and search
grammar analysis
keyword-in-context searching (concordancing)
named-entity extraction
ngrams extraction
parts-of-speech analysis
semantic indexing (also known as “word embedding”)
topic modeling
Given something like a set of scholarly articles, or all the chapters of all the Jane Austen novels, study carrels lend themselves to a supplemental type of reading, where reading is defined as the use and understanding of narrative text.
Toolbox
The Toolbox exploits the structured nature of study carrels, and makes it easy to address questions from the mundane to the sublime. Examples include but are not limited to:
How big is this corpus, and how big is this corpus compared to others?
Sans stop words, what are the most frequent one-word, two-word, etc-word phrases in this corpus?
To what degree does a given word appear in a corpus? Zero times? Many times, and if many, then in what context?
What words can be deemed as keywords for a given text, and what other texts have been classified similarly?
What things are mentioned in a corpus? (Think nouns.)
What do the things do? (Think verbs.)
How are those things described? (Think adjectives.)
What types of entities are mentioned in a corpus? The full names of people? Organizations? Places? Locations? Money amounts? Dates? Times? Works of art? Diseases? Chemicals? Organisms? And given these entities, how are they related to each other?
What are all the noun phrases in a text, and how often do they occur?
What did people say?
What are all the sentences fragments matching the grammar subject-verb-object, and which ones of those fragments match a given regular expression?
Assuming that a word is known by the company it keeps, what words are in the same semantic space (word embedding), or what latent themes may exist in a corpus beyond keywords (topic modeling)?
How did a given idea ebb and flow over time? Who articulated the idea, and how? Where did a given idea manifest itself in the world?
If a given book is denoted as “great”, then what are its salient characteristics, and what other books can be characterized similarly?
What is justice and if murder is morally wrong, then how can war be justified?
What is love, and how do Augustine’s and Rousseau’s definitions of love compare and contrast?
Given a study carrel with relevant content, the Toolbox can be used to address all of the questions outlined above.
Quickstart
The Toolbox requires Python 3, and it can be installed from the terminal with the following command:
pip install reader-toolbox
Once installed, you can invoke it from the terminal like this:
rdr
The result ought to be a help text looking much like this:
Usage: rdr [OPTIONS] COMMAND [ARGS]...
Options:
--help Show this message and exit.
Commands:
browse Peruse <carrel> as a file system Study carrels are sets of...
catalog List study carrels Use this command to enumerate the study...
cluster Apply dimension reduction to <carrel> and visualize the...
concordance A poor man's search engine Given a query, this subcommand...
download Cache <carrel> from the public library of study carrels A...
edit Modify <carrel>'s stop word list When using subcommands such...
get Echo the values denoted by the set subcommand This is useful...
grammars Extract sentence fragments from <carrel> where fragments are...
ngrams Output and list words or phrases found in <carrel> This is...
play Play the word game called hangman.
read Open <carrel> in your Web browser Use this subcommand to...
search Perform a full text query against <carrel> Given words,...
semantics Apply semantic indexing queries against <carrel> Sometimes...
set Configure the location of your study carrels and a subsystem...
sql Use SQL queries against the database of <carrel> Study...
tm Apply topic modeling against <carrel> Topic modeling is the...
Once you get this far, you can run quite a number of different commands:
# browse the remote library of study carrels
rdr catalog -l remote -h
# read a carrel from the remote library
rdr read -l remote homer
# browse a carrel from the remote library
rdr browse -l remote homer
# list all the words in a remote carrel
rdr ngrams -l remote homer
# initialize a local library; accept the default
rdr set
# cache a carrel from the remote library
rdr download homer
# list all two-word phrases containing the word love
rdr ngrams -s 2 -q love homer
# see how the word love is used in context
rdr concordance -q love homer
# list all the subject-verb-object sentence fragments containing love; please be patient
rdr grammars -q love homer
# much the same, but for the word war; will return much faster
rdr grammars -q '\bwar\b' -s homer | more
Summary
The Distant Reader creates data sets called “study carrels”, and study carrels lend themselves to analysis by people as well as computers. The Toolbox is a companion command-line application written in Python. It simplifies the process of answering questions — from the mundane to the sublime — against study carrels.
Posted on August 3, 2021 in Distant Reader by Eric Lease Morgan
The venerable Project Gutenberg is a collection of about 60,000 transcribed editions of classic literature in the public domain, mostly from the Western cannon. A subset of about 30,000 Project Gutenberg items has been cached locally, indexed, and made available through a website called the Distant Reader. The index is freely for anybody and anywhere to use. This blog posting describes how to query the index.
The index is rooted in a technology called Solr, a very popular indexing tool. The index supports simple searching, phrase searching, wildcard searches, fielded searching, Boolean logic, and nested queries. Each of these techniques are described below:
simple searches – Enter any words you desire, and you will most likely get results. In this regard, it is difficult to break the search engine.
phrase searches – Enclose query terms in double-quote marks to search the query as a phrase. Examples include: "tom sawyer", "little country schoolhouse", and "medieval europe".
wildcard searches – Append an asterisk (*) to any non-phrase query to perform a stemming operation on the given query. For example, the query potato* will return results including the words potato and potatoes.
fielded searches – The index has many different fields. The most important include: author, title, subject, and classification. To limit a query to a specific field, prefix the query with the name of the field and a colon (:). Examples include: title:mississippi, author:plato, or subject:knowledge.
Boolean logic – Queries can be combined with three Boolean operators: 1) AND, 2) OR, or 3) NOT. The use of AND creates the intersection of two queries. The use of OR creates the union of two queries. The use of NOT creates the negation of the second query. The Boolean operators are case-sensitive. Examples include: love AND author:plato, love OR affection, and love NOT war.
nested queries – Boolean logic queries can be nested to return more sophisticated sets of items; nesting allows you to override the way rudimentary Boolean operations get combined. Use matching parentheses (()) to create nested queries. An example includes (love NOT war) AND (justice AND honor) AND (classification:BX OR subject:"spiritual life"). Of all the different types of queries, nested queries will probably give you the most grief.
Becase this index is a full text index on a wide variety of topics, you will probably need to exploit the query language to create truly meaningful results.
Posted on July 26, 2021 in Distant Reader by Eric Lease Morgan
This blog posting documents the query syntax for an index of scientific journal articles called CORD-19.
CORD-19 is a data set of scientific journal articles on the topic of COVID-19. As of this writing, it includes more than 750,000 items. This data set has been harvested, pre-processed, indexed, and made available as a part of the Distant Reader. Access to the index is freely available to anybody and everybody.
The index is rooted in a technology called Solr, a very popular indexing tool. The index supports simple searching, phrase searching, wildcard searches, fielded searching, Boolean logic, and nested queries. Each of these techniques are described below:
simple searches – Enter any words you desire, and you will most likely get results. In this regard, it is difficult to break the search engine.
phrase searches – Enclose query terms in double-quote marks to search the query as a phrase. Examples include: "waste water", "circulating disease", and "acute respiratory syndrome".
wildcard searches – Append an asterisk (*) to any non-phrase query to perform a stemming operation on the given query. For example, the query virus* will return results including the words virus and viruses.
fielded searches – The index has many different fields. The most important include: authors, title, year, journal, abstract, and keywords. To limit a query to a specific field, prefix the query with the name of the field and a colon (:). Examples include: title:disease, abstract:"cardiovascular disease", or year:2020. Of special note is the keywords field. Keywords are sets of statistically significant and computer-selected terms akin to traditional library subject headings. The use of the keywords field is a very efficient way to create a small set of very relevant articles. Examples include: keywords:mrna, keywords:ribosome, or keywords:China.
Boolean logic – Queries can be combined with three Boolean operators: 1) AND, 2) OR, or 3) NOT. The use of AND creates the intersection of two queries. The use of OR creates the union of two queries. The use of NOT creates the negation of the second query. The Boolean operators are case-sensitive. Examples include: covid AND title:SARS, abstract:cat* OR abstract:dog*, and abstract:cat* NOT abstract:dog*
nested queries – Boolean logic queries can be nested to return more sophisticated sets of articles; nesting allows you to override the way rudimentary Boolean operations get combined. Use matching parentheses (()) to create nested queries. An example includes ((covid AND title:SARS) OR abstract:cat* OR abstract:dog*) NOT year:2020. Of all the different types of queries, nested queries will probably give you the most grief.
The Distant Reader is a tool for reading. Given an almost arbitrary amount of unstructured data (text), the Reader creates a corpus, applies text mining against the corpus, and returns a structured data set amenable to analysis (“reading”) by students, researchers, scholars, and computers.
The data sets created by the Reader are called “study carrels”. They contain a cache of the original input, plain text versions of the same, many different tab-delimited files enumerating textual features, a relational database file, and a number of narrative reports summarizing the whole. Given this set of information, it is easy to answer all sorts of questions that would have previously been very time consuming to address. Many of these questions are akin to newspaper reporter questions: who, what, when, where, how, and how many.
Using more sophisticated techniques, the Reader can help you elucidate on a corpus’s aboutness, plot themes over authors and time, create maps, create timelines, or even answer sublime questions such as, “What are some definitions of love, and how did the writings of St. Augustine and Jean-Jacques Rousseau compare to those definitions?”
The Distant Reader and its library of study carrels are located at:
These tasks introduce you to the nature of study carrels:
From the library, identify two study carrels of interest, and call them Carrel A and Carrel B. Don’t think too hard about your selections.
Read Carrel A, and answer the following three questions: 1) how many items are in the carrel, 2) if you were to describe the content of the carrel in one sentence, then what might that sentence be, and 3) what are some of the carrel’s bigrams that you find interesting and why.
Read Carrel B, and answer the same three questions.
Answer the question, “How are Carrels A and B similar and different?”
Activity #2: Become familiar with the content of a study carrel
These tasks stress the structured and consistent nature of study carrels:
Download and uncompress both Carrel A and Carrel B.
Count the number of items (files and directories) at the root of Carrel A. Count the number of items (files and directories) at the root of Carrel B. Answer the question, “What is the difference between the two counts?”. What can you infer from the answer?
Open any of the items in the directory/folder named “cache”, and all of the files there ought to be exact duplicates of the original inputs, even if they are HTML documents. In this way, the Reader implements aspects of preservation. A la LOCKSS, “Lots of copies keep stuff safe.”
From the cache directory, identify an item of interest; pick any document-like file, and don’t think too hard about your selection.
Given the name of the file from the previous step, open the file with the similar name but located in the folder/directory named “txt”, and you ought to see a plain text version of the original file. The Reader uses these plain text files as input for its text mining processes.
Given the name of the file from the previous step, use your favorite spreadsheet program to open the similarly named file but located in the folder/directory named “pos”. All files in the pos directory are tab-delimited files, and they can be opened in your spreadsheet program. I promise. Once opened, you ought to see a list of each and every token (“word”) found in the original document as well as the tokens’ lemma and part-of-speech values. Given this type of information, what sorts of questions do you think you can answer?
Open the file named “MANIFEST.htm” found at the root of the study carrel, and once opened you will see an enumeration and description of all the folders/files in any given carrel. What types of files exist in a carrel, and what sorts of questions can you address if given such files?
Activity #3: Create study carrels
Anybody can create study carrels, there are many ways to do so, and here are two:
Click the Create button, and the Reader will begin to do its work.
Wait patiently, and along the way the Reader will inform you of its progress. Depending on many factors, your carrels will be completed in as little as two minutes or as long as an hour.
Finally, repeat Activities #1 and #2 with your newly created study carrels.
Extra credit activities
The following activities outline how to use a number of cross-platform desktop/GUI applications to read study carrels:
Print any document found in the cache directory and use the traditional reading process to… read it. Consider using an active reading process by annotating passages with your pen or pencil.
Download Wordle from the Wayback Machine, a fine visualization tool. Open any document found in the txt directory, and copy all of its content to the clipboard. Open Wordle, paste in the text, and create a tag cloud.
Download AntConc, a cross-platform concordance application. Use AntConc to open one more more files found in the txt directory, and then use AntConc to find snippets of text containing the bigrams identified in Activity #1. To increase precision, configure AntConc to use the stopword list found in any carrel at etc/stopwords.txt.
Download OpenRefine, a robust data cleaning and analysis program. Use OpenRefine to open one or more of the files in the folder/directory named “ent”. (These files enumerate named-entities found in your carrel.) Use OpenRefine to first clean the entities, and then use it to count & tabulate things like the people, places, and organizations identified in the carrel. Repeat this process for any of the files found in the directories named “adr”, “pos”, “wrd”, or “urls”.
Extra extra credit activities
As sets of structured data, the content of study carrels can be computed against. In other words, programs can be written in Python, R, Java, Bash, etc. which open up study carrel files, manipulate the content in ways of your own design, and output knowledge. For example, you could open up the named entity files, select the entities of type PERSON, look up those people in Wikidata, extract their birthdates and death dates, and finally create a timeline illustrating who was mentioned in a carrel and when they lived. The same thing could be done for entities of type GRE (place), and a map could be output. A fledgling set of Jupyter Notebooks and command-line tools have been created just for these sorts of purposes, and you can find them on GitHub:
Every study carrel includes an SQLite relational database file (etc/reader.db). The database file includes all the information from all tab-delimited files (named-entities, parts-of-speech, keywords, bibliographics, etc.). Given this database, a person can either query the database from the command-line, write a program to do so, or use GUI tools like DB Browser for SQLite or Datasette. The result of such queries can be elaborate if-then statement such as “Find all keywords from documents dated less than Y” or “Find all documents, and output them in a given citation style.” Take a gander at the SQL file named “etc/queries.sql” to learn how the database is structured. It will give you a head start.
Summary
Given an almost arbitrary set of unstructured data (text), the Distant Reader outputs sets of structured data known as “study carrels”. The content of study carrels can be consumed using the traditional reading process, through the use of any number of desktop/GUI applications, or programmatically. This document outlined each of these techniques.
Embrace information overload. Use the Distant Reader.









 Over the past few years, I have written a number of blog postings which describe a thing called the
Over the past few years, I have written a number of blog postings which describe a thing called the This tiny blog posting outlines a sort of recipe for the use of text mining to address research questions. Through the use of this process the student, researcher, or scholar can easily supplement the traditional reading process.
This tiny blog posting outlines a sort of recipe for the use of text mining to address research questions. Through the use of this process the student, researcher, or scholar can easily supplement the traditional reading process. The Distant Reader Toolbox is a command-line tool for interacting with data sets created by the Distant Reader — data sets affectionally called “study carrels”. See:
The Distant Reader Toolbox is a command-line tool for interacting with data sets created by the Distant Reader — data sets affectionally called “study carrels”. See: The venerable
The venerable 
